
{kind=link}
Optimizing Local LLMs for Real-Time Machine Vision on Edge AI Platforms
AI-powered machine vision is moving beyond detection, classification, OCR, barcode reading, and defect inspection. The next step is adding local LLM intelligence that can help interpret inspection results, support operator interaction, and connect machine vision output with higher-level decision logic.
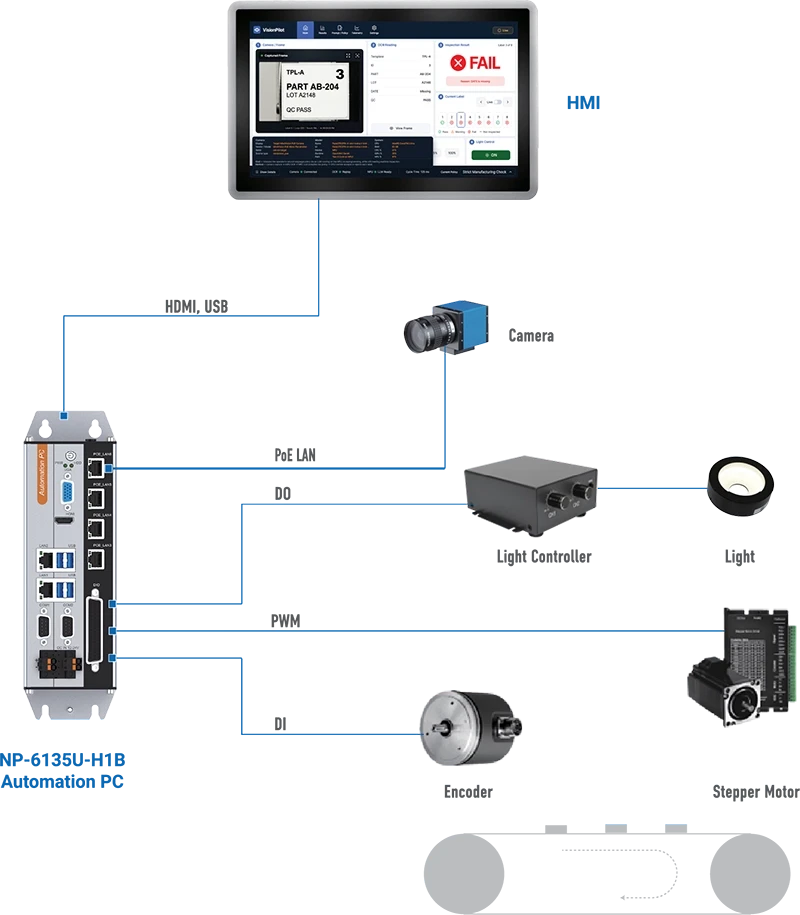
At Automate, NODKA is demonstrating a reference machine vision AI workflow built around this idea: a local LLM-assisted vision system running on Edge AI IPC hardware, using optimized software to make better use of CPU, iGPU, and NPU resources. It is a technology reference demo showing what is possible when modern industrial IPC hardware is paired with the latest AI software optimization techniques.
This demo is not a packaged NODKA application. It is a reference architecture designed to show how OEMs, machine builders, and system integrators can use compact Edge AI platforms to support responsive machine vision intelligence with lower power consumption, smaller system footprint, and more cost-effective deployment.

Why Local LLMs Matter for Machine Vision
Large language models are changing how users interact with machines. In a machine vision environment, a local LLM can help translate inspection context into more understandable output, support machine-level QA, or assist with rule interpretation.
But factory systems have different requirements than cloud AI applications.
Industrial machine vision systems need low latency, local processing, data privacy, stable hardware, and predictable integration with cameras, I/O, triggers, and automation systems. Sending every inspection result to a cloud model is not always practical, especially when the system must run close to the production line.
That is why local LLM optimization for machine vision is important.
The goal is not to make every Edge AI IPC behave like a large AI server. The goal is to use the right architecture so a compact local model can perform a bounded, useful task while the rest of the system handles validation, structure, and execution deterministically.
Edge AI IPCs Are About Smarter Workload Distribution
Many machine vision systems are deployed across multiple inspection points. In these environments, hardware selection is about more than peak AI performance. Power consumption, thermal design, enclosure size, lifecycle stability, serviceability, and total deployment cost are equally important.
Modern Edge AI IPC platforms create a practical option by combining CPU, integrated GPU, and NPU resources in one compact industrial system. CPU platforms such as Intel Core Ultra make it possible to distribute workloads more efficiently:
- The CPU handles deterministic logic, validation, system control, and coordination.
- The iGPU can support vision and AI workloads where appropriate.
- The NPU can accelerate efficient local AI inference.
- Optimized software determines how well the hardware is actually used.
This heterogeneous architecture can help reduce system complexity, power draw, and deployment cost while still supporting advanced machine vision and local AI workflows.
NODKA’s Automate demo is designed to show this direction: real-time-oriented LLM-assisted machine vision becomes more practical when the AI workload is optimized for the available edge hardware.
How the Reference Demo Works
The demo uses a hybrid Edge AI architecture:
Local LLM candidate generation → structured output → CPU validation → policy compilation → controlled execution
In this design, the local LLM does not directly control the machine vision workflow. Instead, it generates a compact candidate output. That output is checked, validated, and translated by deterministic CPU-side logic before it can be used by the downstream system.
This is where the real-time advantage comes from.
A pure open-ended LLM or VLM workflow may ask the model to interpret the image, reason through the inspection logic, decide the next action, format the answer, and correct its own mistakes in one large inference loop. That can increase latency and make runtime behavior harder to predict, especially on resource-limited edge hardware.
The VisionPilot-style compiler approach divides the problem differently. The local LLM performs a bounded task: generating a structured candidate. The CPU then performs fast deterministic work: schema validation, rule checking, policy compilation, and execution gating.
This architecture is important because real-time machine vision systems cannot depend on free-form AI text. The system needs structured, validated, machine-readable output.
The key idea is simple:
The LLM proposes. The CPU-side compiler verifies. The executor only receives approved structure.
By moving validation and policy compilation to the CPU, the system reduces repeated model calls, limits open-ended self-correction loops, and creates a more predictable path for real-time-oriented machine vision workflows.
Technologies Used for Local LLM Optimization
Local LLM on Edge AI Hardware
The demo is optimized around a small local LLM running on Edge AI hardware resources. Compact models such as Microsoft’s Phi-4-Mini show the industry trend toward smaller language models that can support useful reasoning tasks in more resource-constrained environments.
For machine vision applications, this helps move LLM-assisted intelligence closer to cameras, machines, and inspection stations while reducing dependency on cloud processing.
CPU, iGPU, and NPU Workload Distribution
Instead of relying only on one compute engine, the system uses a balanced Edge AI approach. The NPU supports efficient AI inference, the iGPU can assist with vision and AI workloads where appropriate, and the CPU handles deterministic validation, policy compilation, and system coordination.
For real-time-oriented machine vision, CPU performance is especially important because the CPU handles deterministic validation, camera/trigger coordination, I/O handling, and the compiler-style logic that turns AI output into usable policy. This reduces the burden on the local LLM and helps keep the overall system responsive.
OpenVINO and AI Software Optimization
Intel OpenVINO and OpenVINO GenAI help developers optimize and deploy AI models across available compute resources, including CPU, integrated GPU, and NPU.
For Edge AI machine vision, this matters because performance is not only about raw TOPS. It is also about how efficiently the software stack uses the hardware. Optimization technologies such as model conversion, quantization, runtime scheduling, and hardware-aware inference help make local AI more practical on industrial IPC platforms.
Structured Output and Grammar-Constrained Generation
Instead of allowing the model to generate uncontrolled free-form text, the demo uses structured-output techniques to guide the model toward valid machine-readable results.
This direction is supported by recent work on structured output generation, grammar-constrained decoding, and efficient structured generation engines such as XGrammar.
In practical terms, structured output helps reduce parsing errors and makes the LLM output easier to validate before it is used by the rest of the system. It helps enforce structure, but it does not replace semantic validation. That is why the CPU-side validation and compiler-style policy layer remain important.
Pydantic-Based Validation
Pydantic is used as part of the CPU-side validation layer. It helps enforce required fields, data types, ranges, allowed values, nested structures, and structured policy rules.
This is especially important for industrial AI because a result that “sounds right” is not enough. The output must pass defined checks before moving forward. Pydantic also supports responsive edge performance by making validation explicit, repeatable, and deterministic compared with asking the model to repeatedly inspect and repair its own output.
Custom Python Policy Compiler
The validated output is translated into a controlled policy structure using a custom Python compiler-style layer. This approach helps separate LLM reasoning from execution logic, making the system more predictable and easier to integrate into machine vision workflows.
This compiler-style layer converts flexible AI output into a compact policy that can be checked and executed quickly, helping prevent the model from becoming the bottleneck for every runtime decision.
Why This Matters for OEMs and System Integrators
For OEMs and system integrators, the value of local LLMs in machine vision is not just the model itself. The value is the architecture.
A properly optimized Edge AI IPC can support new AI-assisted functions while keeping the system local, compact, power-efficient, and deployment-friendly. This can help enable:
- Real-time-oriented local machine vision QA
- Operator-friendly inspection explanations
- AI-assisted rule interpretation
- Faster deterministic validation at the machine level
- Reduced cloud dependency
- Lower power consumption at distributed inspection nodes
- More cost-effective deployment across multiple stations
- Better scalability for OEM and system integrator designs
- Practical Edge AI deployment without overbuilding every node
This approach gives machine builders another option for applications where local AI intelligence is useful, but the system also needs to remain compact, efficient, responsive, and cost-sensitive.
See the Reference Demo at Automate
NODKA’s Automate demo is designed to show how local LLMs, machine vision, Edge AI, and industrial IPC hardware can work together in a practical reference architecture.
The message is not that every AI vision system should use the same hardware. The message is that the right combination of CPU, iGPU, NPU, and optimized AI software can make real-time-oriented LLM-assisted machine vision more accessible for edge deployments.
As AI moves deeper into factory automation, the future will not only be about larger models or bigger systems. It will also be about smarter software architecture, better workload distribution, lower power consumption, faster deterministic validation, and industrial IPC platforms designed for real-world deployment.